【Python入門ブログ】四則演算をやる方法【動画付き】
mintson
【公式】夜猫ミントのブログ


人口ピラミッドは、年齢と性別ごとの人口分布を視覚化するのに便利なグラフです。
この記事では、Pythonを使って1935年の人口ピラミッドを作成する方法を紹介します。
今回使用するライブラリは以下の通りです:
pandas:Excelファイルのデータを読み込むmatplotlib:人口ピラミッドを描画するopenpyxl:Pythonで Excelファイル(.xlsx, .xlsm) を扱うことが可能まず、必要なライブラリをインストールしていない場合は、以下のコマンドでインストールできます。
pip install pandas matplotlib openpyxl numpyまず、Excelファイルからデータを取得します。
人口動態調査はe-Statからダウンロードできますが、そのExcelファイルのフォーマットはPythonで分析するにはちょっと手間なので以下のように必要なデータだけをコピペして、分析しやすくします。
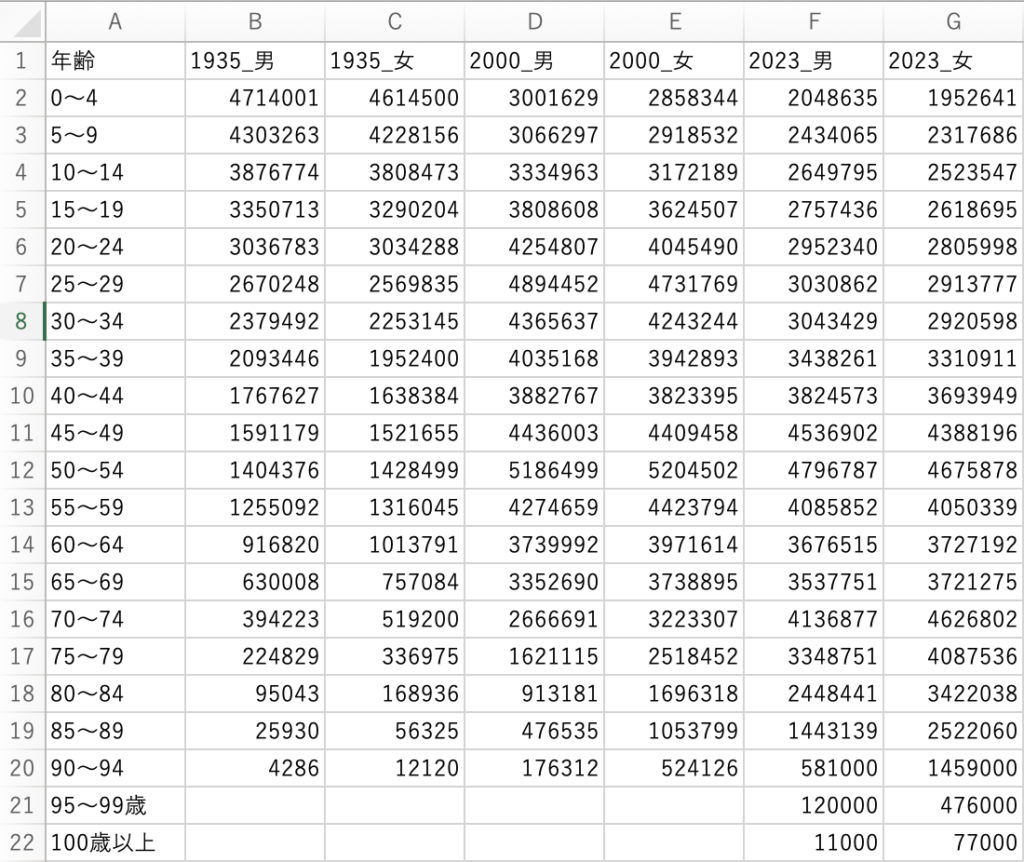
ここでは、japan_population.xlsx というExcelファイルを使い、適切なシートを読み込みます。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# Excelファイルのパス
xlsx_file_path = 'japan_population.xlsx' # 実際のファイルパスを指定
# Excelファイルを読み込む(適切なシート名またはインデックスを指定)
df = pd.read_excel(xlsx_file_path, sheet_name=0)
# 列名を文字列に変更(もし数値であれば)
df.columns = df.columns.astype(str)
#フォントを日本語対応させるためにMeiryoに変更
plt.rcParams['font.family'] = 'Meiryo'
# データの確認(欠損値がないかなど)
print(df.head())このコードでは、Excelファイルを読み込み、列名を文字列に変換することでアクセスしやすくしています。また、head() を使ってデータの先頭5行を確認します。
次に、1935年の人口ピラミッドを作成します。
# グラフのサイズを指定
plt.figure(figsize=(12, 8))
# 1935年の人口ピラミッド
plt.barh(df['年齢'], -df['1935_男'], label='1935年 男性', alpha=0.7, color='#1f77b4')
plt.barh(df['年齢'], df['1935_女'], label='1935年 女性', alpha=0.7, color='#ff7f0e')
# ラベルとタイトル
plt.xlabel('人口')
plt.ylabel('年齢')
plt.title('1935年の人口ピラミッド')
plt.legend()
plt.grid(axis='x', linestyle='--')
# 最大人口を100万人単位に切り上げ
max_population = int(np.ceil(max(df['2023_男'].max(), df['2023_女'].max()) / 1000000) * 1000000)
# -max_population から max_population まで100万人単位で目盛りを設定
tick_values = np.arange(-max_population, max_population + 1, 1000000)
# X軸のラベルを「万」単位で表示
plt.xticks(tick_values, [f"{abs(x) // 10000}万" for x in tick_values])
# グラフの表示
plt.show()df['2023_男'].max() と df['2023_女'].max() で、それぞれの最大人口を取得。
max(…) を使って 男性と女性のどちらか大きい方の値 を取得。np.ceil(… / 1000000) * 1000000 で 100万人単位に切り上げ。6,780,000 / 1,000,000 = 6.78np.ceil(6.78) = 7 となり、7,000,000 になる。np.arange(start, stop, step) を使い、目盛りの位置を作成。
-max_population から max_population + 1 まで 100万単位 (1000000) で刻む。plt.xticks(目盛りの位置, ラベルのリスト) で X軸の目盛りラベルを設定。abs(x) // 10000 を使って、値を「万」単位に変換。
abs(-7,000,000) // 10,000 = 700 → "700万"abs(0) // 10,000 = 0 → "0万"abs(7,000,000) // 10,000 = 700 → "700万"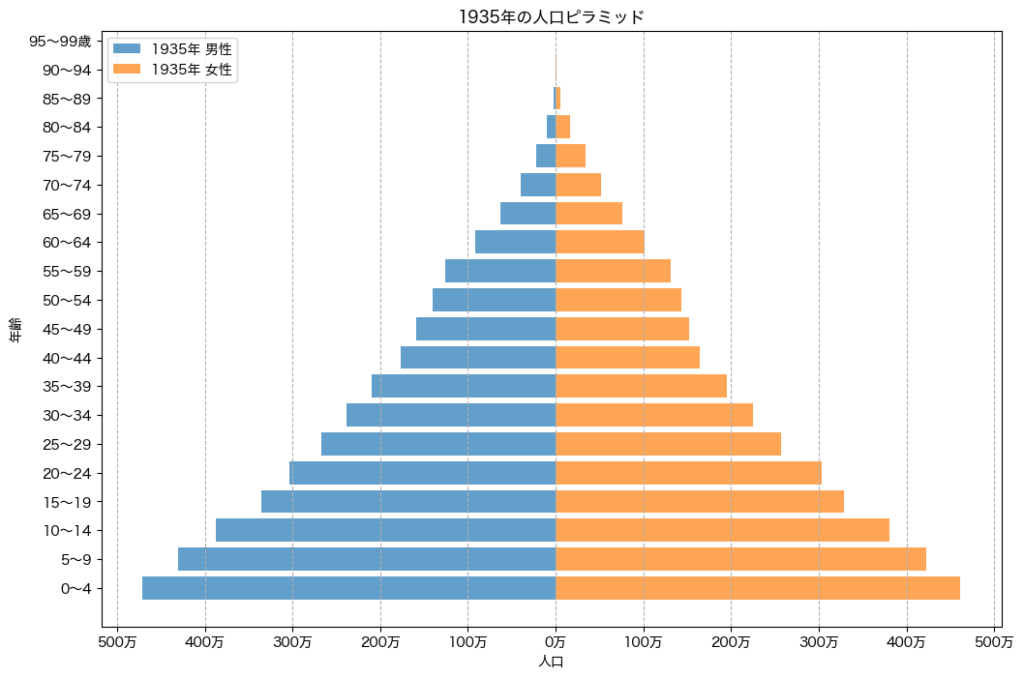
このようにいe-Statの政府統計情報の人口動態調査を用いると1935年の日本は富士山型で富士山のように底辺の幅が広く頂点になるにつれ狭まることがお分かりだと思います。
出典:政府統計の総合窓口(e-Stat)(https://www.e-stat.go.jp/)
※「人口動態調査」を加工して作成
